Without a non-linearity, stacking layers is pointless — two linear maps collapse into one. The non-linearity \(\phi\) is what makes depth mean something: \[\mathbf{h} = \phi(\mathbf{W}\mathbf{x} + \mathbf{b}).\] The early-era choices are sigmoid and tanh. Their saturation — flat tails where the derivative vanishes — is the seed of the vanishing-gradient problem taken up in the next chapter.
A neuron is a weighted sum followed by a non-linearity. The artificial-neuron chapter focused on the weighted sum; this one is about why the non-linearity is not optional. Strip it out and a deep network is algebraically identical to a shallow one — no amount of stacking buys representational power. The non-linearity is the single ingredient that lets composition build complexity.
It also matters because the choice of activation shapes how gradients flow. The early activations (sigmoid, tanh) saturate, and that saturation is exactly what makes deep networks hard to train — the bridge to gradient flow.
5.2 The mechanism
5.2.1 Without non-linearity, depth collapses
A linear layer is \(\mathbf{h} = \mathbf{W}\mathbf{x}\). Stack two:
The composition is itself a single linear map\(\mathbf{W} = \mathbf{W}_2\mathbf{W}_1\). No depth, no gain. Inserting a non-linearity \(\phi\) between layers breaks this collapse — the network can now represent functions no single linear map can.
import numpy as nprng = np.random.default_rng(0)W1 = rng.normal(size=(4, 2))W2 = rng.normal(size=(1, 4))x = rng.normal(size=(2,))two_layers = W2 @ (W1 @ x) # stacked, no non-linearityone_layer = (W2 @ W1) @ x # a single equivalent linear mapprint("two linear layers:", two_layers)print("single equivalent:", one_layer)print("identical:", np.allclose(two_layers, one_layer))
two linear layers: [1.23783565]
single equivalent: [1.23783565]
identical: True
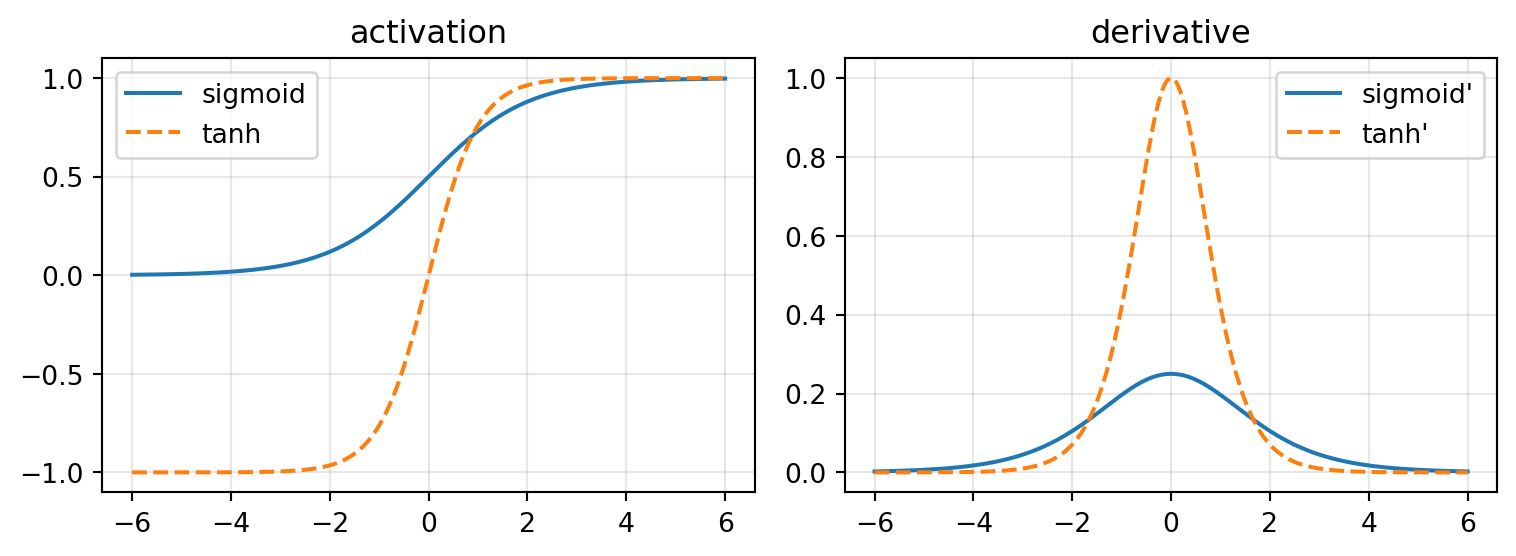
Two things to note. First, both saturate: for large \(|z|\) the output flattens and the derivative goes to zero. Second, tanh is zero-centered while sigmoid is not — sigmoid’s all-positive outputs bias the gradients of the next layer, which is why tanh is generally preferred as a hidden activation (LeCun et al., 1998).
The activations are flat in the tails — saturated. There, the derivative (right panel) is near zero.
\(\sigma'\) peaks at just \(0.25\); \(\tanh'\) at \(1.0\). A chain of sigmoids multiplies numbers \(\le 0.25\) together — gradients shrink fast with depth.
This is the mechanism, not a side note: it is why deep sigmoid/tanh networks were historically hard to train, and the direct setup for the next chapter.
WarningPitfall: saturation kills gradients
A neuron driven deep into saturation (large \(|z|\)) has a near-zero derivative, so almost no gradient flows back through it — it stops learning. Picking activations, initializations, and normalizations that keep units out of saturation is a recurring theme for the rest of the book.
5.3 Application & impact
Sigmoid and tanh are no longer the default hidden activation — modern nets use ReLU and its descendants (Modern Activations). But neither is legacy: both survive in specific, load-bearing roles.
every deep network; formalized with the MLP next chapter
5.3.2 Concretely, where the lineage lands
LSTM gates are sigmoids: each gate outputs a value in \((0,1)\) that multiplies a signal — “let none through” to “let all through.”
A binary classifier’s output is a sigmoid feeding the binary cross-entropy of chapter 02 — i.e. logistic regression.
Modern hidden layers abandoned sigmoid/tanh precisely because of the saturation shown above; that story is told in Modern Activations.
NoteKey takeaway
Non-linearity is the ingredient that makes depth worth having. The foundational choices — sigmoid and tanh — work, but their saturating tails choke gradients in deep stacks. That single weakness motivates both the vanishing-gradient analysis (next) and the modern activations that replaced them later in the timeline.