Improving Zero-Shot Translation of Low-Resource Languages
TL;DR — A multilingual model can translate language pairs it never saw in training, but poorly. We let the model learn from its own zero-shot output, iteratively — gaining ~9 BLEU over the baseline and beating a two-model pivot, with no parallel data for the target pair.
🏆 This paper received the Best Paper Award at IWSLT 2017.
The Problem
Multilingual NMT models can translate between directions they were never explicitly trained on — zero-shot translation. It’s a remarkable property, but in low-resource settings the quality of those zero-shot directions is weak. The usual workaround is pivoting: translate through a high-resource bridge language (e.g., Italian → English → Romanian), which doubles inference cost and compounds errors. The question: can a single multilingual model improve its own zero-shot directions directly, without parallel data for them?
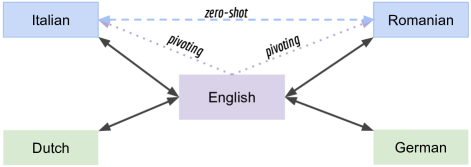
Approach
We use a simple iterative self-training loop. The multilingual model generates translations for the zero-shot directions. These outputs are imperfect — they often contain mixed-language tokens from the shared vocabulary — but they carry signal. We add them back to the original parallel data and re-train. Each round, the model learns from its own increasingly better output, bootstrapping quality in directions it never had supervision for.
Key Results
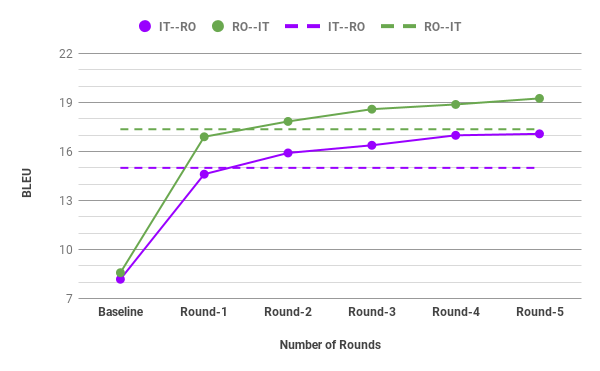
- ~9 BLEU improvement over the baseline multilingual model on the zero-shot directions.
- Up to 2.08 BLEU over a pivoting mechanism that uses two separate bilingual models — while needing only one model and one decoding pass.
- A slight gain in the non-zero-shot directions too, suggesting the self-training doesn’t degrade supervised quality.
Why It Matters
For low-resource languages, parallel data for every direction simply doesn’t exist. This shows a model can extend its own coverage from the data it already has — cheaper than pivoting and without new supervision. The idea anticipates later self-training / back-translation strategies in multilingual MT.
Details & Resources
- Paper: IWSLT 2017 (ACL Anthology) · arXiv
- Code: github.com/surafelml/improving-zeroshot-nmt
- Slides: IWSLT 2017 talk
- Award: 🏆 Best Paper, IWSLT 2017
- Citation: S. M. Lakew, Q. F. Lotito, M. Turchi, M. Negri, M. Federico. Proceedings of the 14th International Workshop on Spoken Language Translation, pp. 35–41, Tokyo, 2017.