Authors
Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoye, Marc’Aurelio Ranzato
Overview
Data scarcity is among the main challenges for training a usable Neural Machine Translation(NMT) model. Despite the progress made for a high-resource language (such as; English-German) pair, most languages are characterized by the absence of parallel data to train an NMT system. As my first series of paper review and writing a post I will summarize the “Phrase-Based & Neural Unsupervised Machine Translation”, to be presented at EMNLP18. Authors suggest two model variants; i) Phrase-based and ii) Neural.
Illustration
Both the Phrase-based and Neural rely on three core (#P1, #P2, and #P3) principles, consequently outperforming state-of-the-art approaches on unsupervised translation.
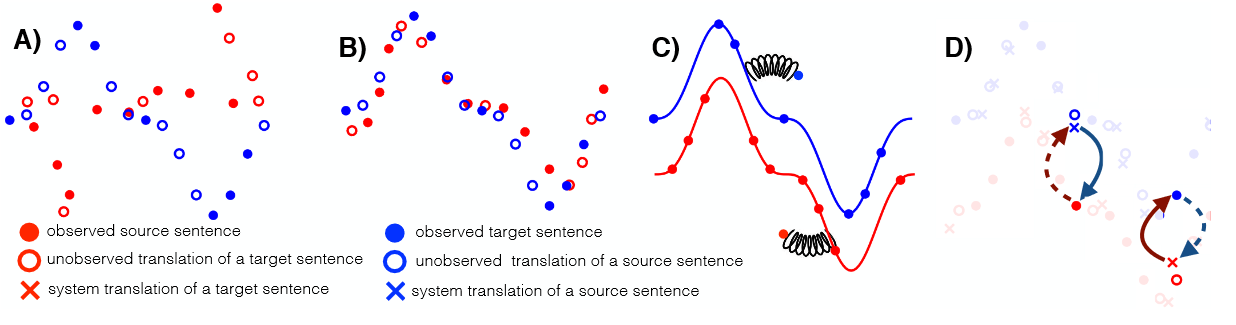
The illustration aims to visualize the idea behind the three principles:
– A) shows two monolingual datasets distribution (see the legend).
– B) Initialization: the two distributions are roughly aligned, with mechanism like word-by-word translation.
– C) Language Modeling (LM): is learned for each domain. The LM’s is then utilized for denoise examples.
– D) Back-translation: a source &rarr target inference stage is followed by a target–>source inference to reconstruct the examples back to the original language. A similar procedure is applied in the reverse/dual translation direction to get the feedback signals for optimizing the target–>source and source–>target models.
P1: Model Initialization
-
The aim is to learn first level (such as; word-by-word) translations
-
In the Neural case, i) jointly learn BPE model, ii) apply BPE, and iii) learning token embeedings to initialize the encoder-decoder lookup table, whereas for the Phrase-Based the initial phrase-tables are populated using a bilingual dictionary build from monolingual data.
-
Note: if the languages are distant learning, learning bilingual dictionary might be required in the Neural scenario.
P2: Language Modeling
- Trains LM both for the source and target sides.
- Used to apply substitution and word reordering, which is expected to improve the final translation task.
- Denoising autoencoding strategy is used to train the LM’s for the Neural, whereas KenLM is utilized to train an n-gram LM’s for the Phrase-based approach.
P3: Iterative Back-Translation
- Following Sennrich et al., 2015, the goal is to generate the source segments for the target monolingual data.
- The artificial source paired with the target creates a parallel data that will change the unsupervised task to a supervised one.
- Thus, by repeating the inference stage with the latest model, the two models learn to generate a better source side artificial data. (See here for more on iterative-learning in a dual-task).
Algorithms
Integrating the above three principles, the Neural and Phrase-Based algorithms are given, where S and T representes source and target examples, and language models trained using source and target monolingual data are represented as Ps-t and Pt->s.
Neural

Phrase-Based

Results
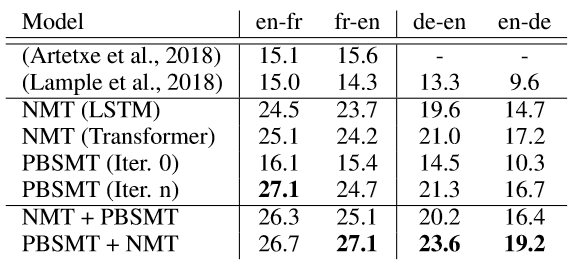
Experimental are done using the well know WMT16 En<>De and WMT14 En<>Fr benchmarks. The combination of the PBSMT and NMT showed to give the best results (see the last row).
My Thoughts
- First of all, unsupervised MT task is a necessary and promising research direction if one truly want to use MT to tackle communication barriers. Imagine there exists more than 7000 languages, and most don’t have parallel data at all.
- Turning unsupervised MT task to the supervised version seems the best strategy to incrementally improve through the iterative learning procedure.
- Would be great to see the approach in a distant source-target language pair and for languages with less comparable monolingual corpora.
More on Unsupervised MT
If you are interested and want to explore more about unsupervised MT approaches, check out the following works:
- Ravi and Knight (2011), Deciphering Foreign Language.
- He et al., (2016), Dual Learning for Machine Translation
- Artetxe et al., (2018), Unsupervised Neural Machine Translation.
- Lample et al., (2018), Unsupervised Machine Translation Using Monolingual Corpora Only.