TL;DR — Instead of training a new NMT model from scratch for every language pair, we let a trained model grow: expand its vocabulary on the fly and transfer existing parameters. Gains of +3.85 to +13.63 BLEU, reaching higher quality after only ~4% of the training steps.
The Problem
Adding a new language pair to an NMT system usually means training a fresh model — expensive, slow, and especially wasteful in low-resource settings where data is scarce. Worse, a fixed vocabulary baked in at training time can’t accommodate the new language’s tokens. Can we instead reuse what a trained model already knows and extend it incrementally?
Approach
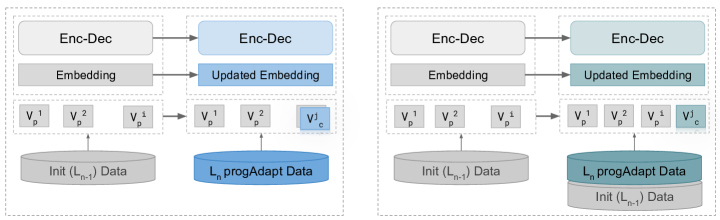
We introduce a shared dynamic vocabulary: the model’s vocabulary can expand as new data arrives, adding new items only when they aren’t already covered, while transferring parameters from the initial model. We evaluate two scenarios:
- Adapt — repurpose a trained single-pair model to a new language pair (
progAdapt). - Grow — continuously add new pairs to build up a multilingual model over time (
progGrow).
Key Results
- +3.85 up to +13.63 BLEU across five languages and directions, at training sizes of just 5k and 50k parallel sentences.
- Compared to training from scratch, the transfer approach reaches higher performance after only ~4% of the total training steps — a large convergence-time saving.
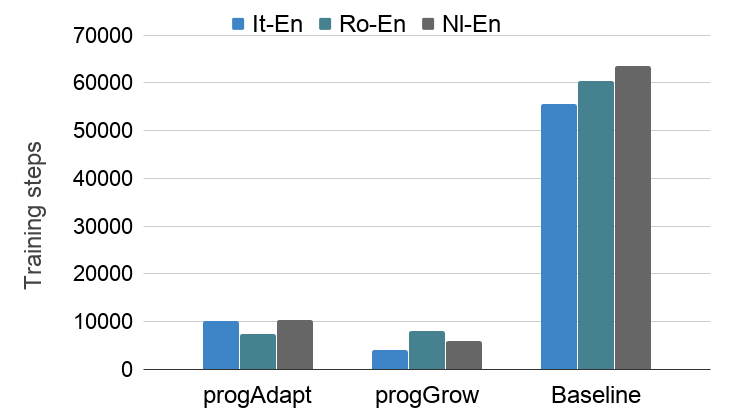
progAdapt and progGrow need a fraction of the from-scratch Baseline.Why It Matters
This reframes multilingual NMT as something you incrementally grow rather than retrain. For low-resource languages — where every training hour and every sentence pair counts — transferring parameters through a dynamic vocabulary makes adding a language cheap and fast. The idea connects directly to later work on adapting multilingual NMT to unseen languages.
Details & Resources
- Paper: IWSLT 2018 (ACL Anthology) · arXiv
- Code: github.com/surafelml/adapt-mnmt
- Citation: S. M. Lakew, A. Erofeeva, M. Negri, M. Federico, M. Turchi. Proceedings of the 15th International Workshop on Spoken Language Translation (IWSLT), Bruges, Belgium, 2018.